Imaging modalities such as Computed Tomography (CT)
and Positron Emission Tomography (PET) are key in cancer detection,
inspiring Deep Neural Networks (DNN) models that merge these scans
for tumor segmentation. When both CT and PET scans are available,
it is common to combine them as two channels of the input to the seg-
mentation model. However, this method requires both scan types during
training and inference, posing a challenge due to the limited availability
of PET scans, thereby sometimes limiting the process to CT scans only.
Hence, there is a need to develop a flexible DNN architecture that can
be trained/updated using only CT scans but can effectively utilize PET
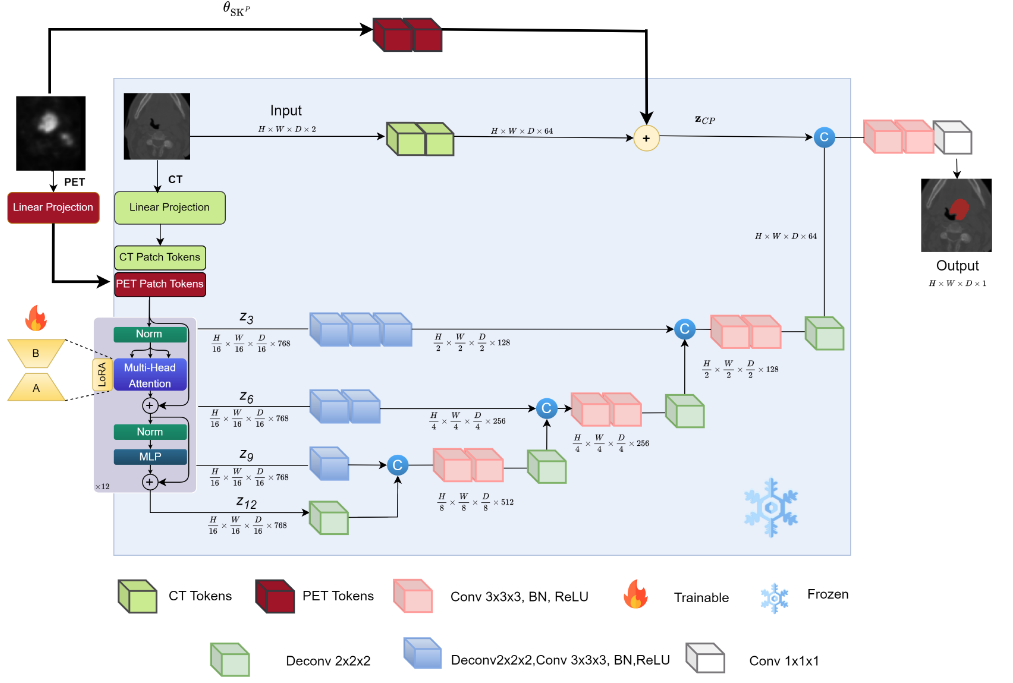
scans when they become available. In this work, we propose a parameter-
efficient multi-modal adaptation (PEMMA) framework for lightweight
upgrading of a transformer-based segmentation model trained only on
CT scans to also incorporate PET scans. The benefits of the proposed
approach are two-fold. Firstly, we leverage the inherent modularity of
the transformer architecture and perform low-rank adaptation (LoRA)
of the attention weights to achieve parameter-efficient adaptation. Sec-
ondly, since the PEMMA framework attempts to minimize cross-modal
entanglement, it is possible to subsequently update the combined model
using only one modality, without causing catastrophic forgetting of the
other modality. Our proposed method achieves comparable results with
the performance of early fusion techniques with just 8% of the train-
able parameters, especially with a remarkable +28% improvement on
the average dice score on PET scans when trained on a single modality.
Paper Link: https://arxiv.org/pdf/2404.13704